
- Notebook: Django: Automating Common Tasks
- Speaker:
- Date Created: Aug. 31, 2024, 12:46 a.m.
- Owner: Rosilie
Web scraping is an automatic method to obtain large amounts of data from websites (see full documentation here)
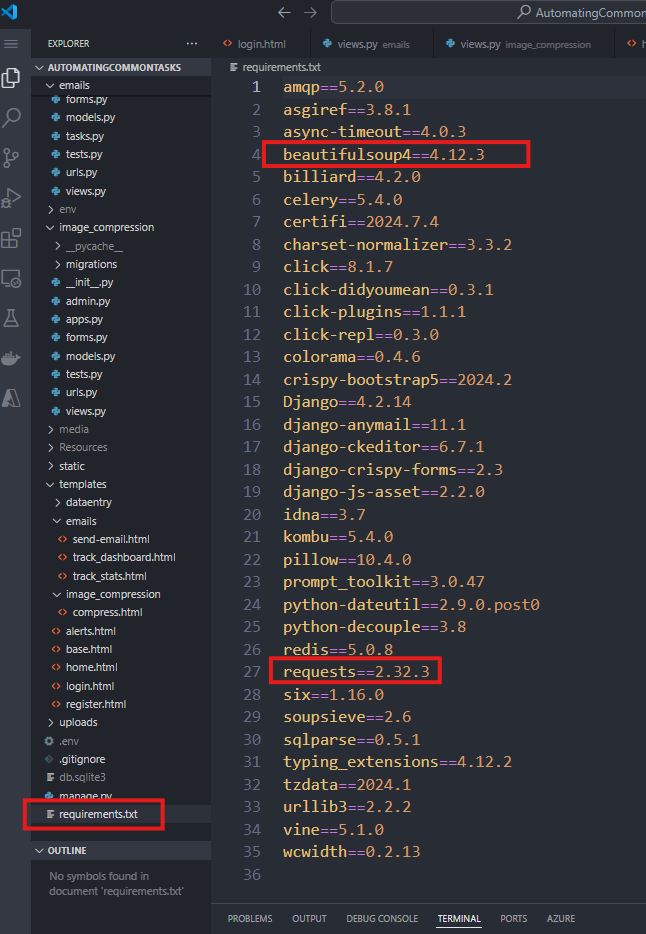
1. To start, we need the libraries BEAUTIFULSOUP (which we previously download) and REQUEST Django library. Install these packages if these are NOT present in your REQUIREMENTS.TXT
$ pip install requests
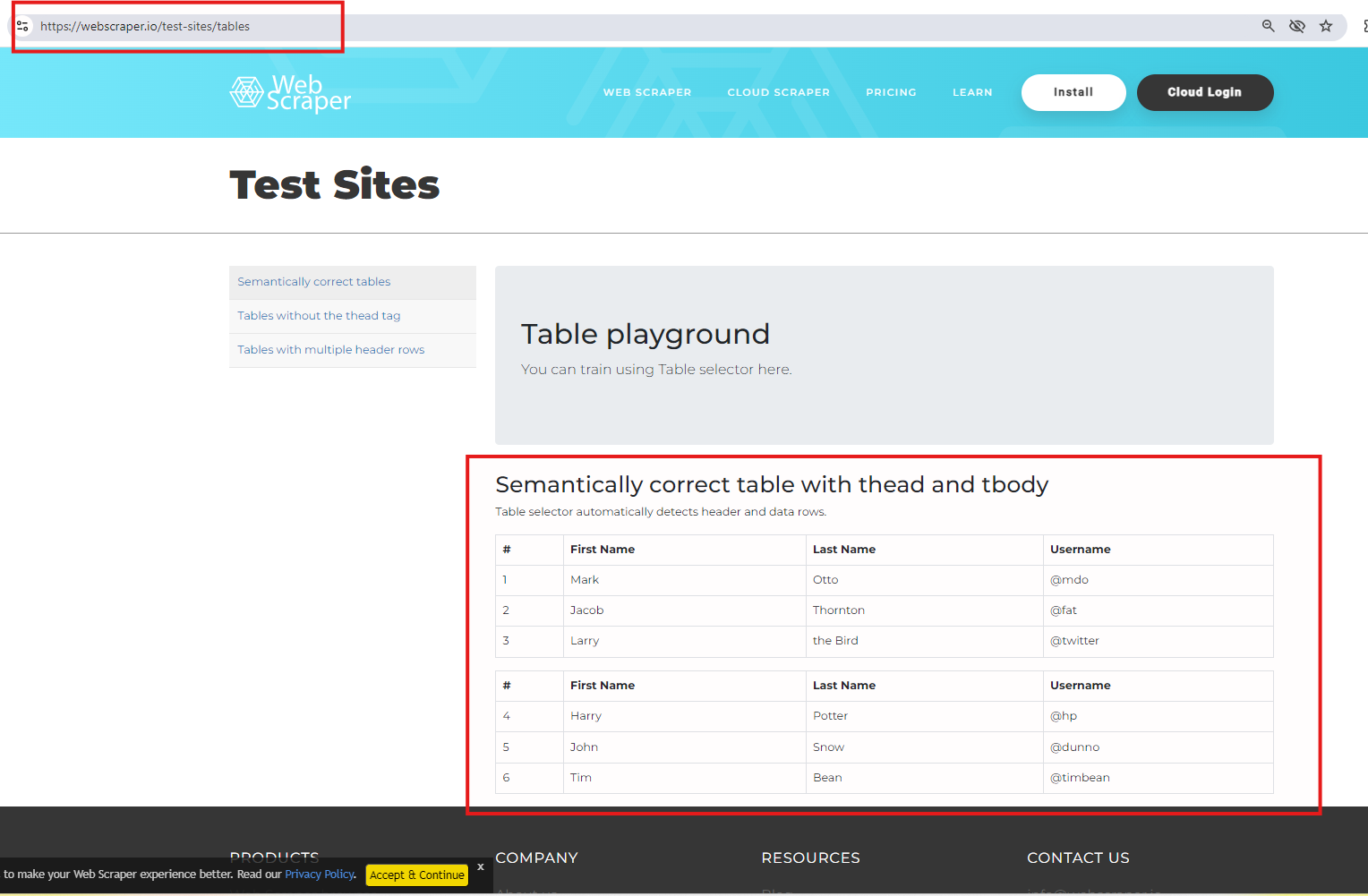
2. Use the website, WEBSCRAPERS.IO for the TEST SITES.
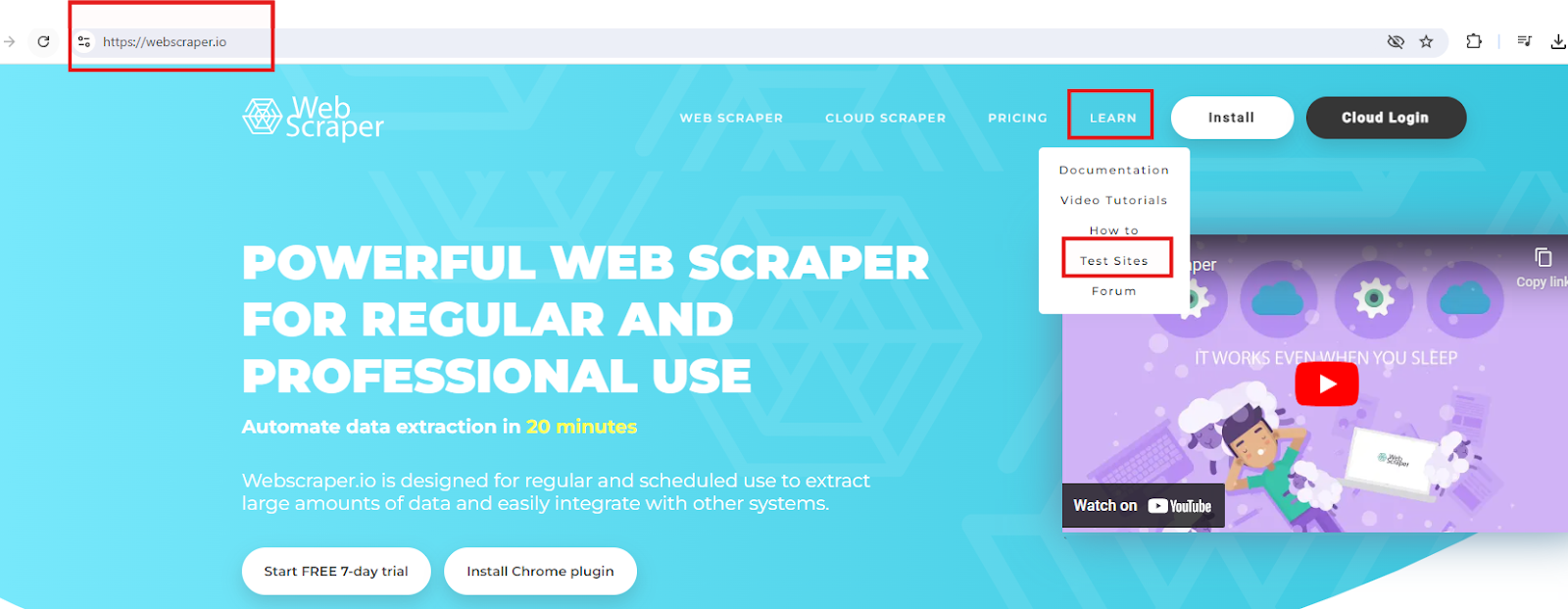
Use the TABLE PLAYGROUND for testing.
3. In the root directory, create a new file, TEST.PY and update:
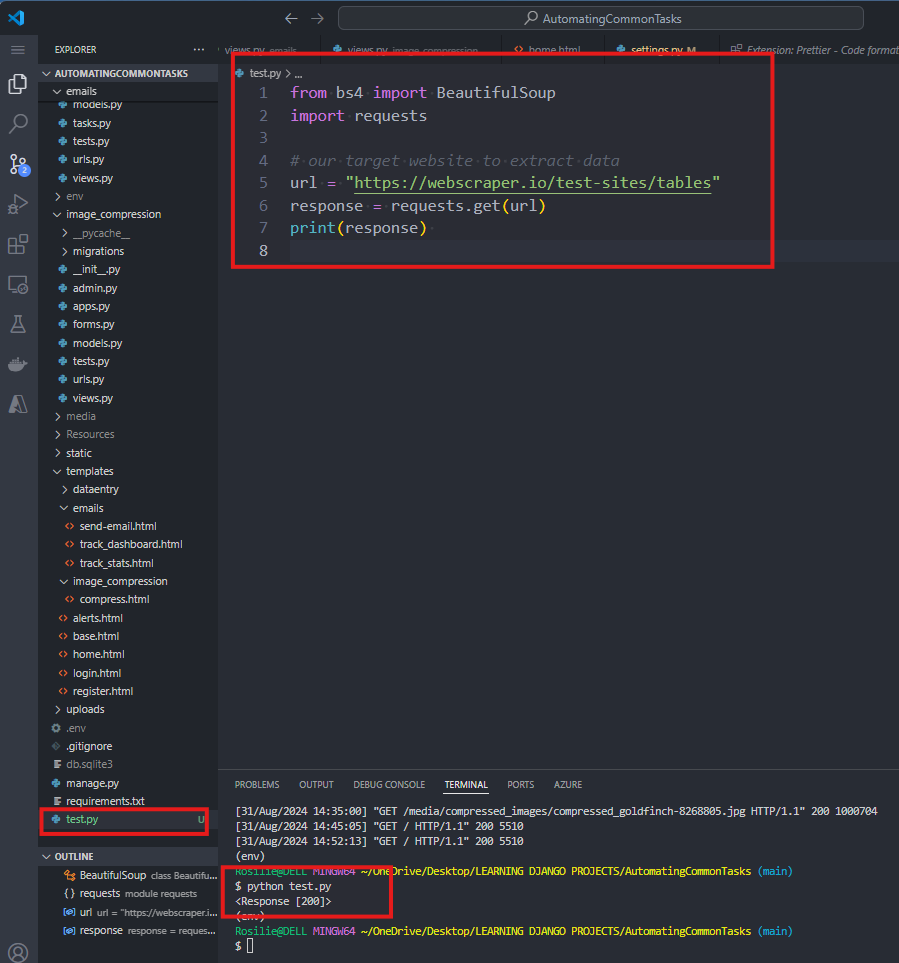
4. Run this file using and it returns 200 - MEANING OK.
$ python test.py

5. Use this as your guide for HTTP RESPONSES:

6. To get the website's HTML code, we type:
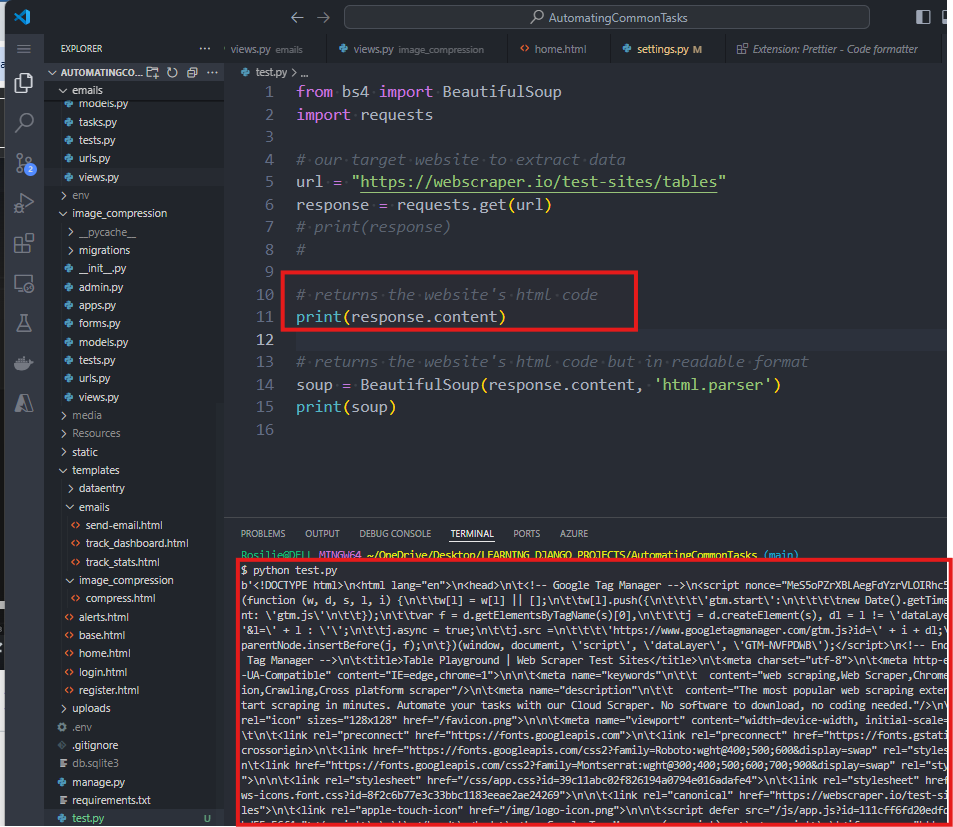
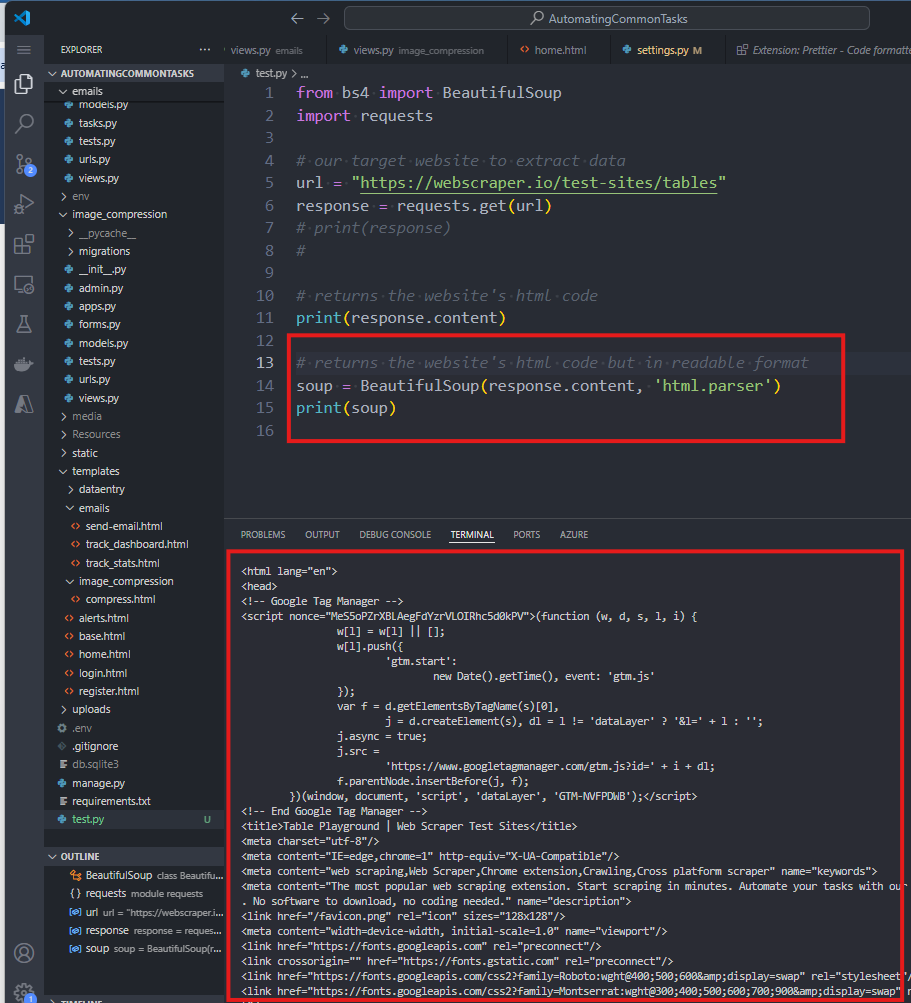
7. If we want to read the website's code in a more readable format, we can use BeautifulSoup.
8. To extract only certain portions of the website like H1 headings only
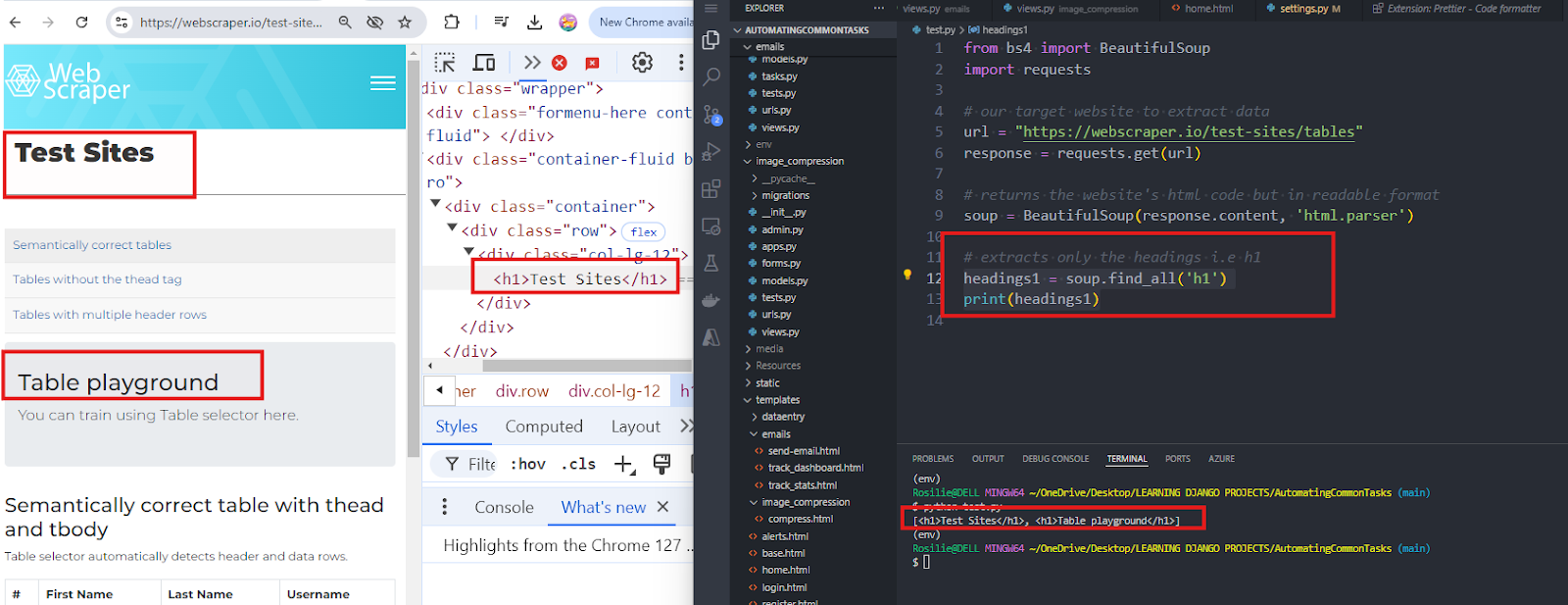
9. To extract the images:
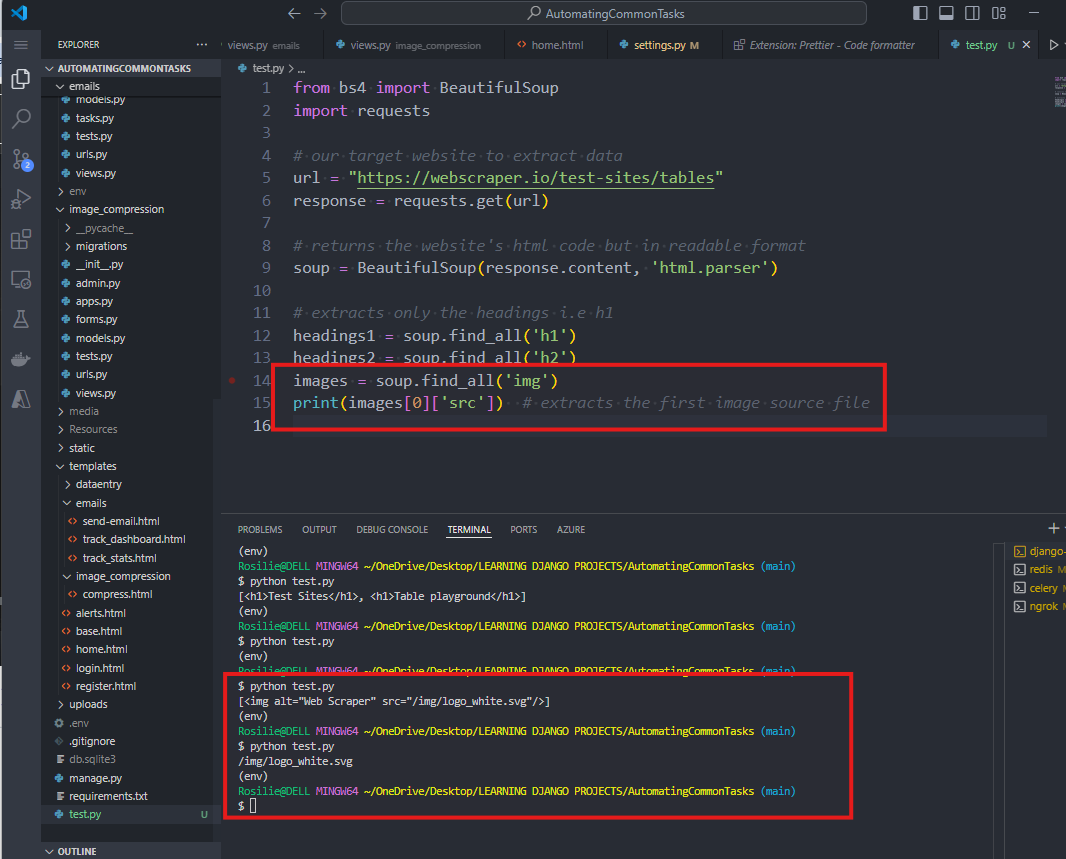
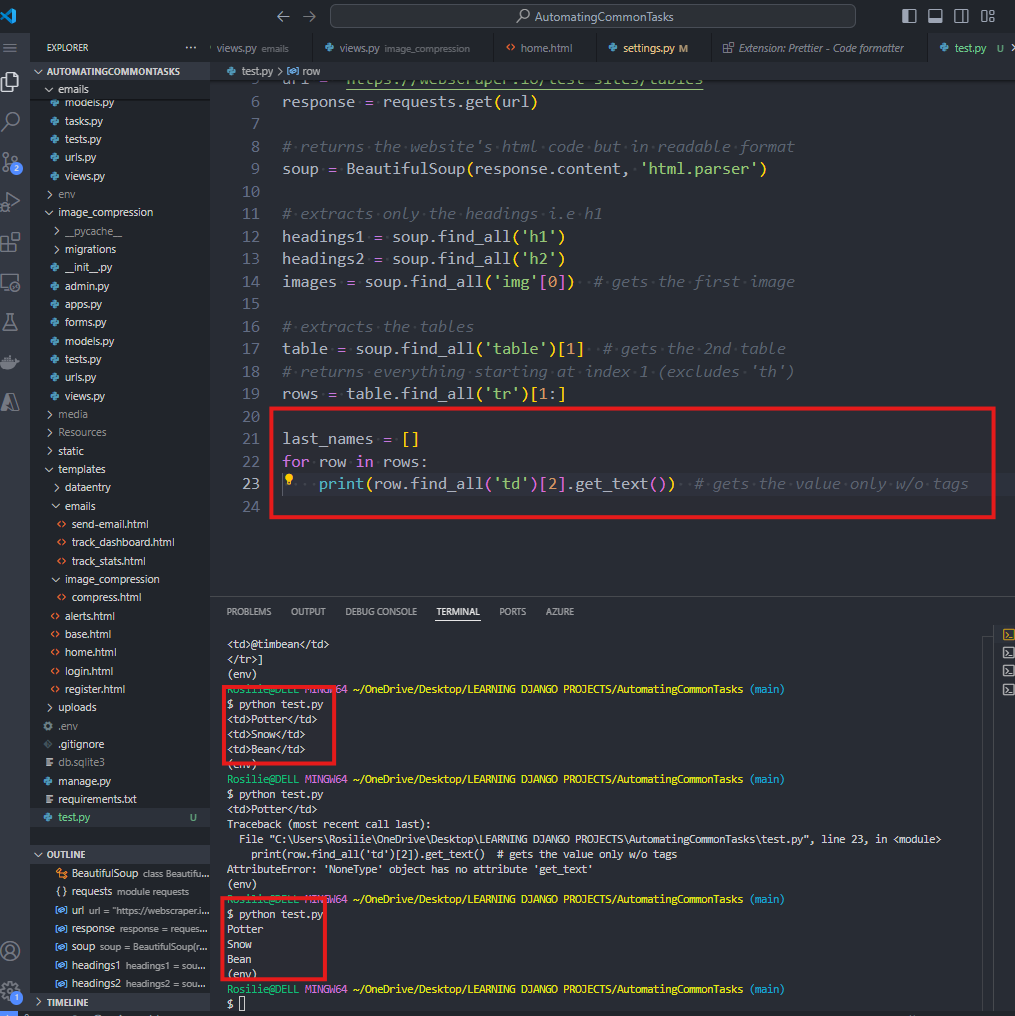
10. To extract the information from the website's tables:
11. Extract only the LASTNAME OF THE SECOND TABLE:
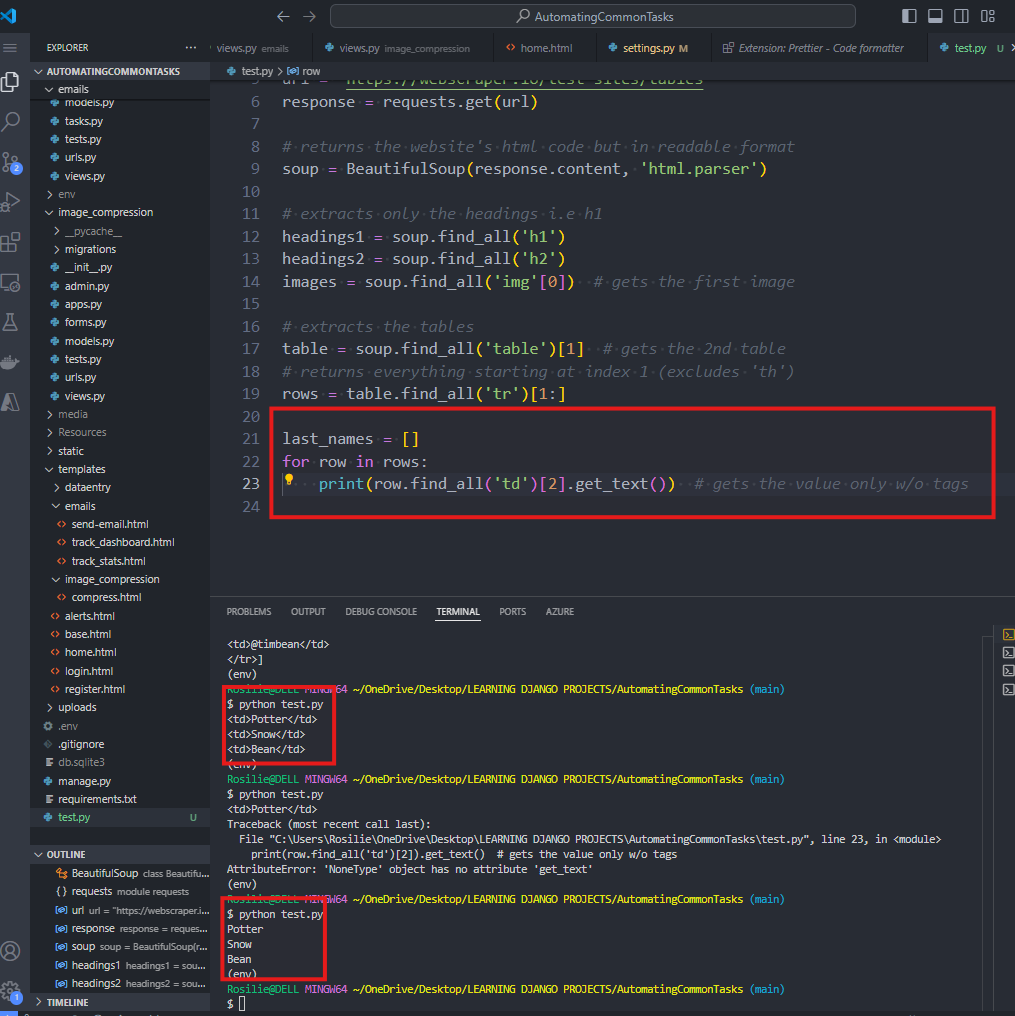
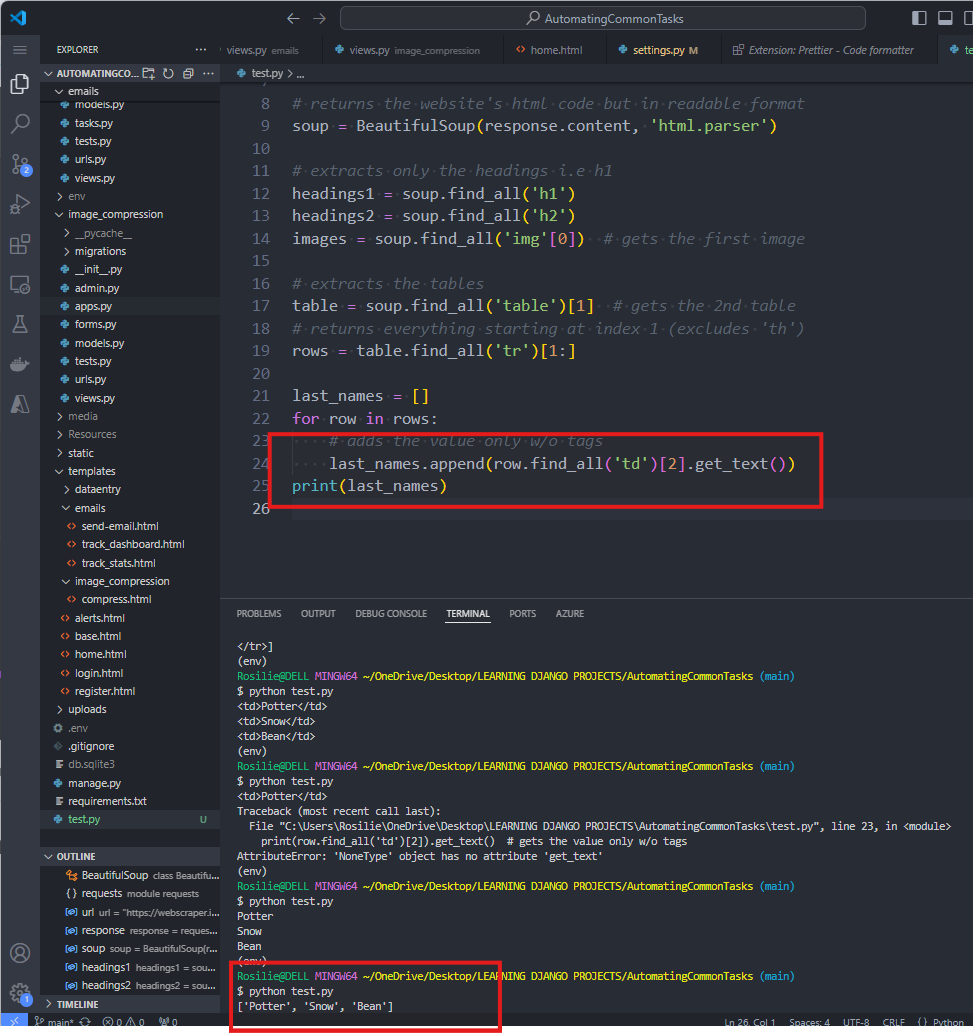
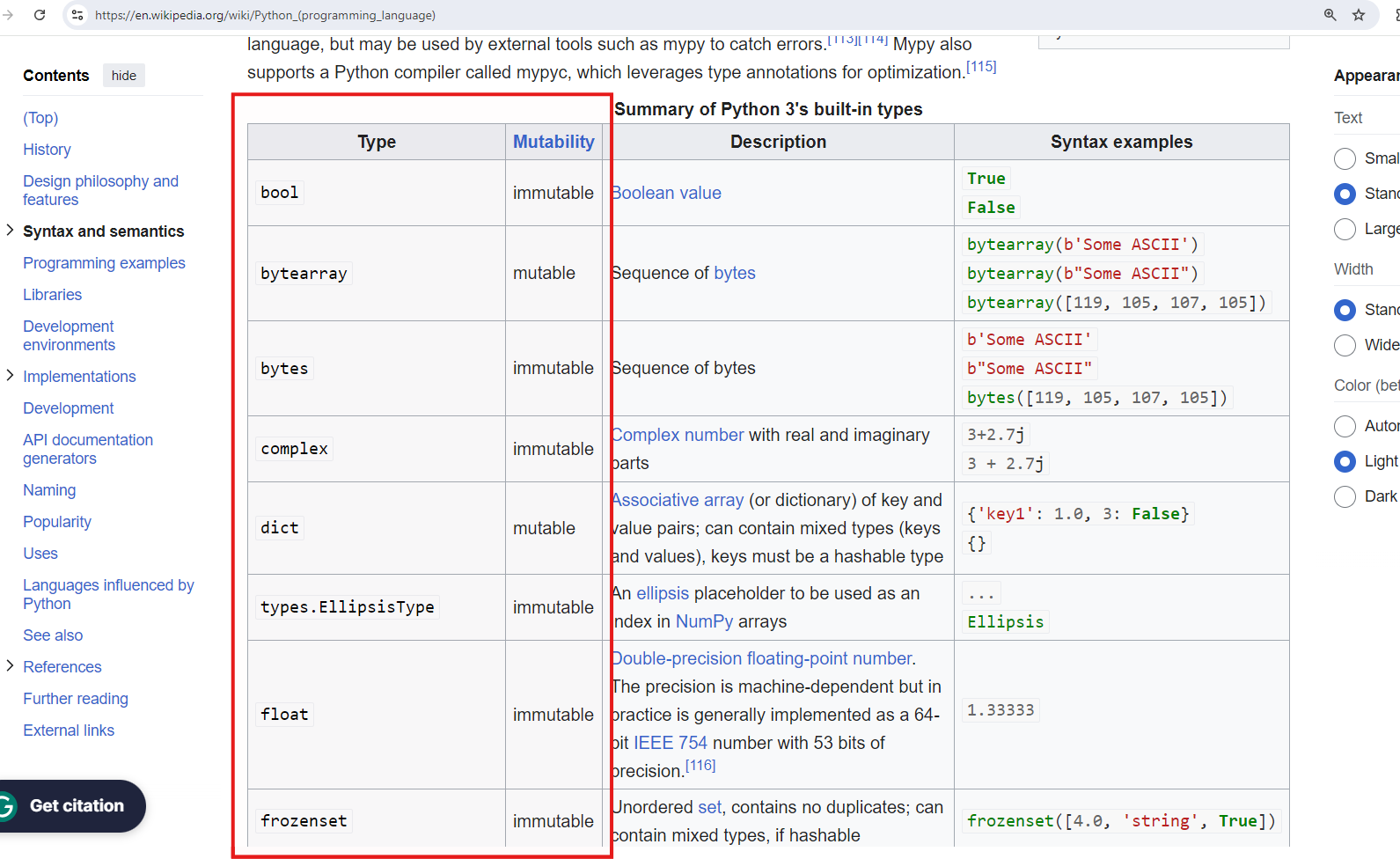
WEBSITE # 2: WIKIPEDIA ON PYTHON
The goal is to categorize the data types according to MUTABLE OR IMMUTABLE
12. We can also use the CLASS name to find an element on the website. So, the table uses a classname 'WIKIPEDIA'
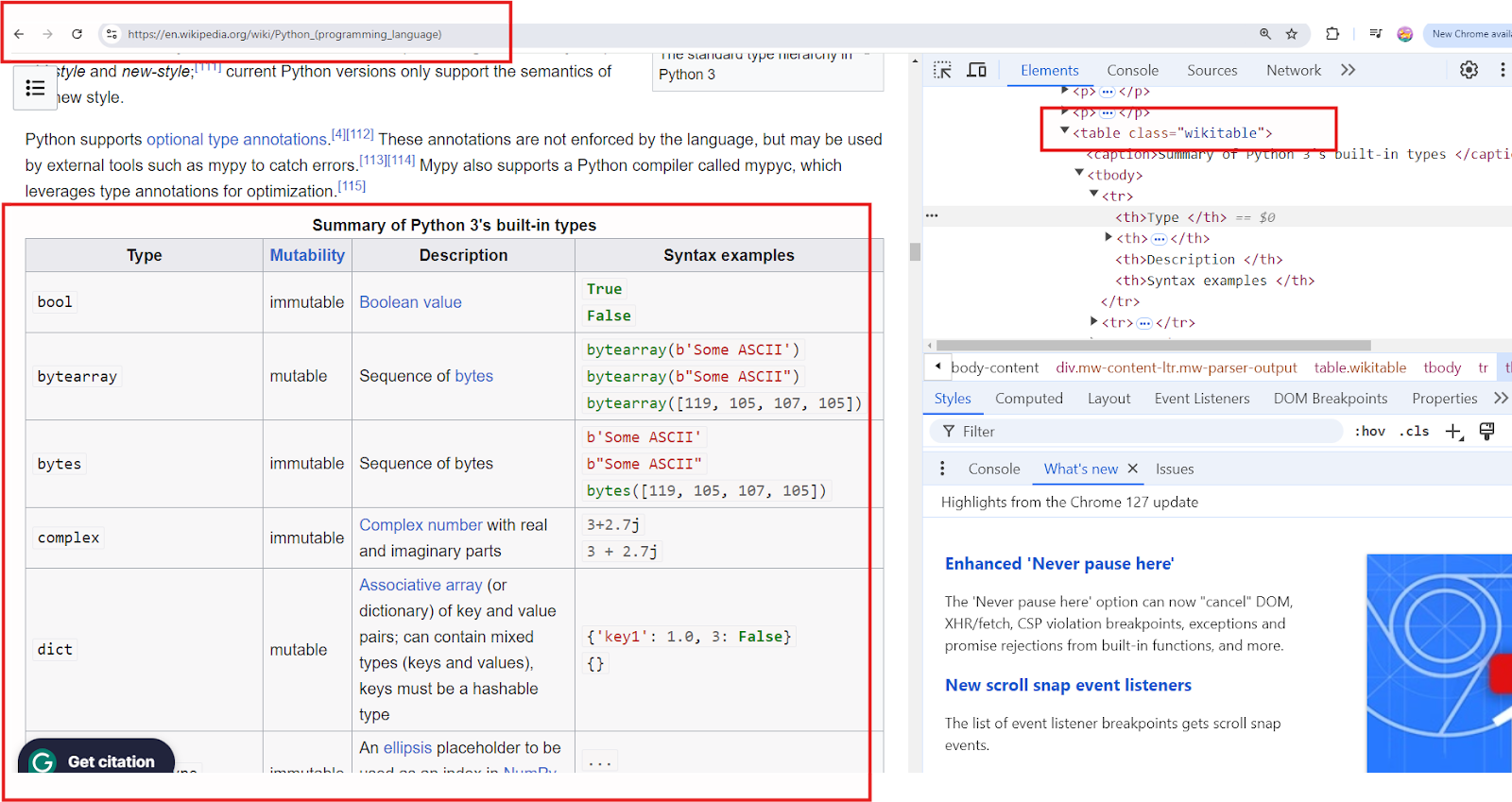
We can update our TEST.PY AS:
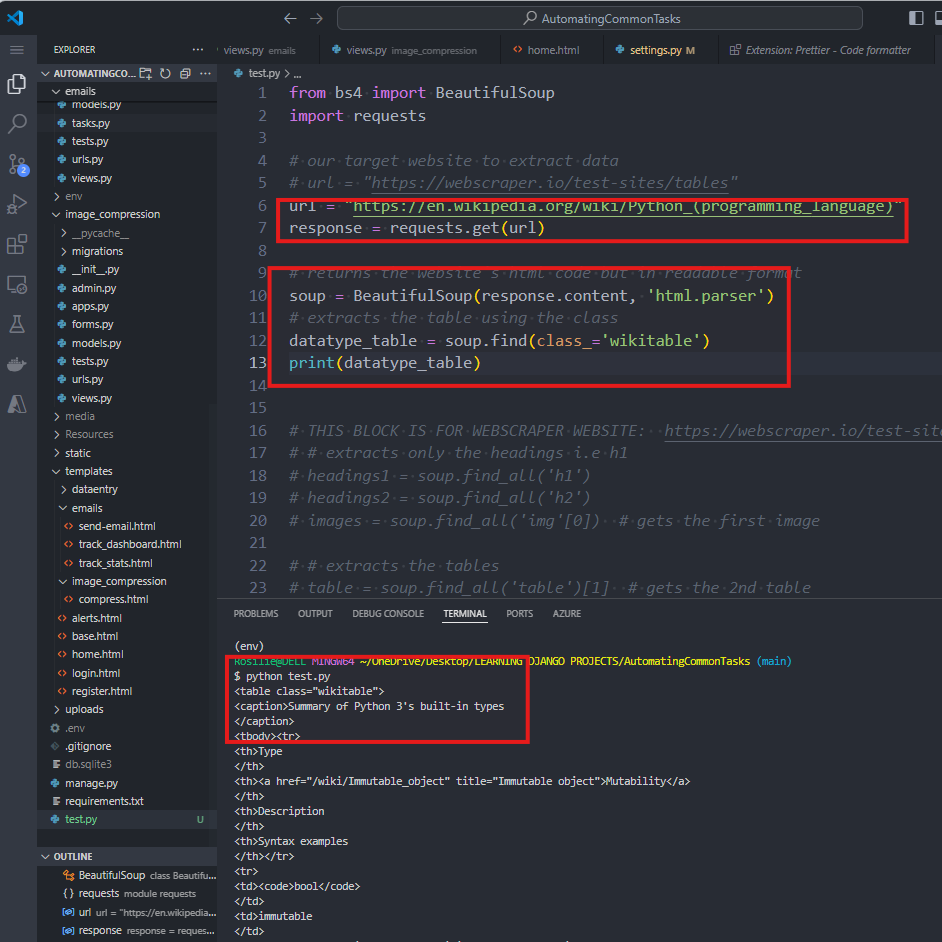
13. Each data type has a tag 'TD' inside the 'TBODY.' We need to use this info then in our TEST.PY. Each table column can be accessed using an INDEX POSITION where INDEX 0 means our first column, INDEX 1 means our second column.
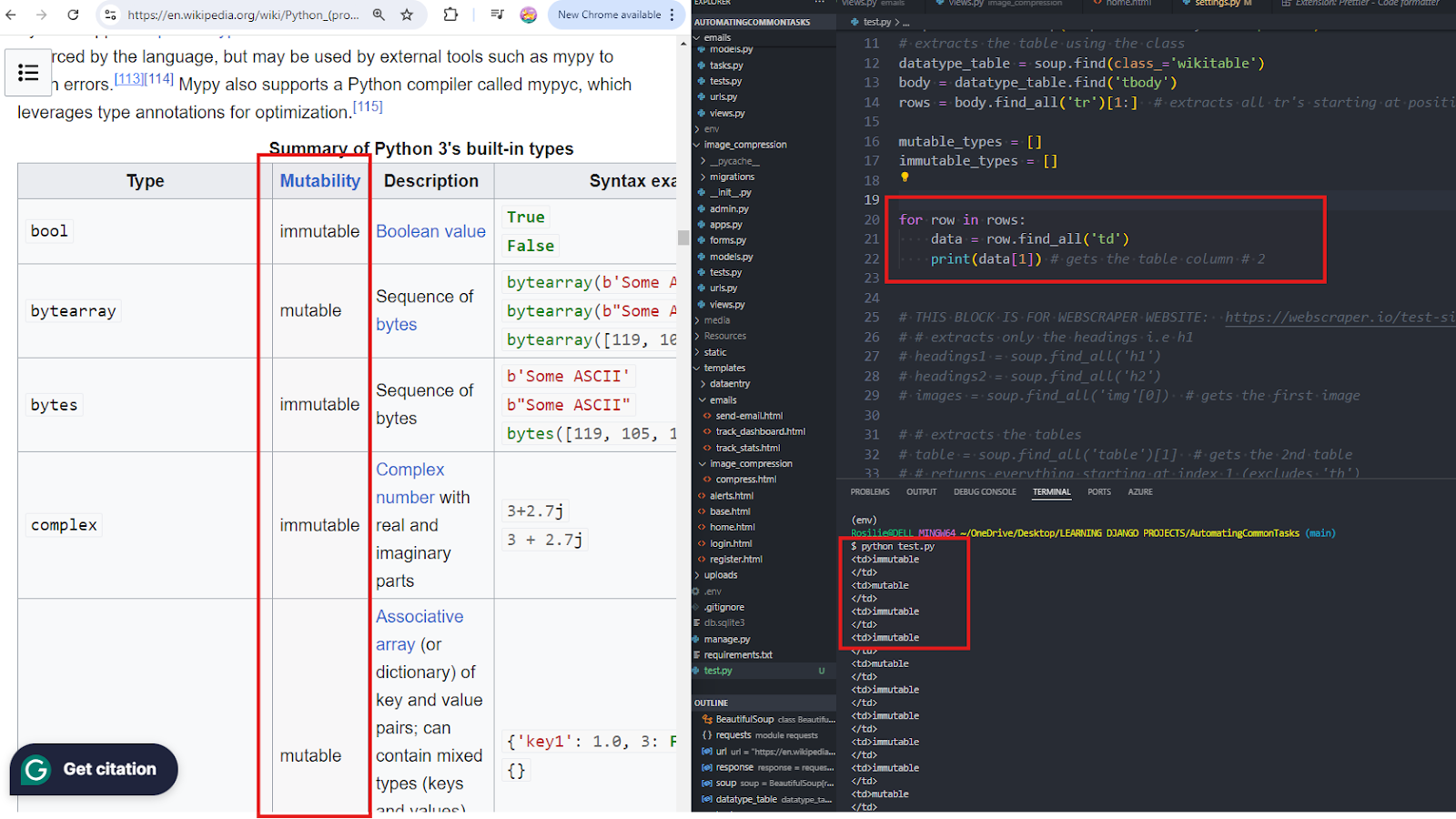
14. Update TEST.PY as:
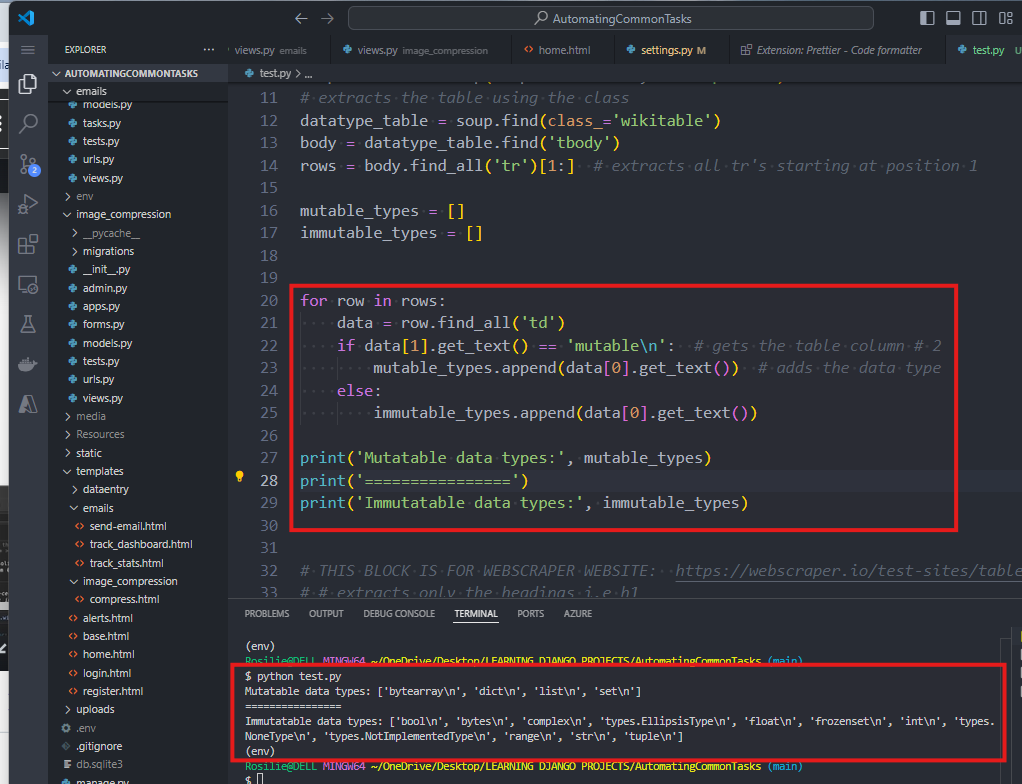
15. To remove the NEWLINE (\n), we can use the STRIP FUNCTION:
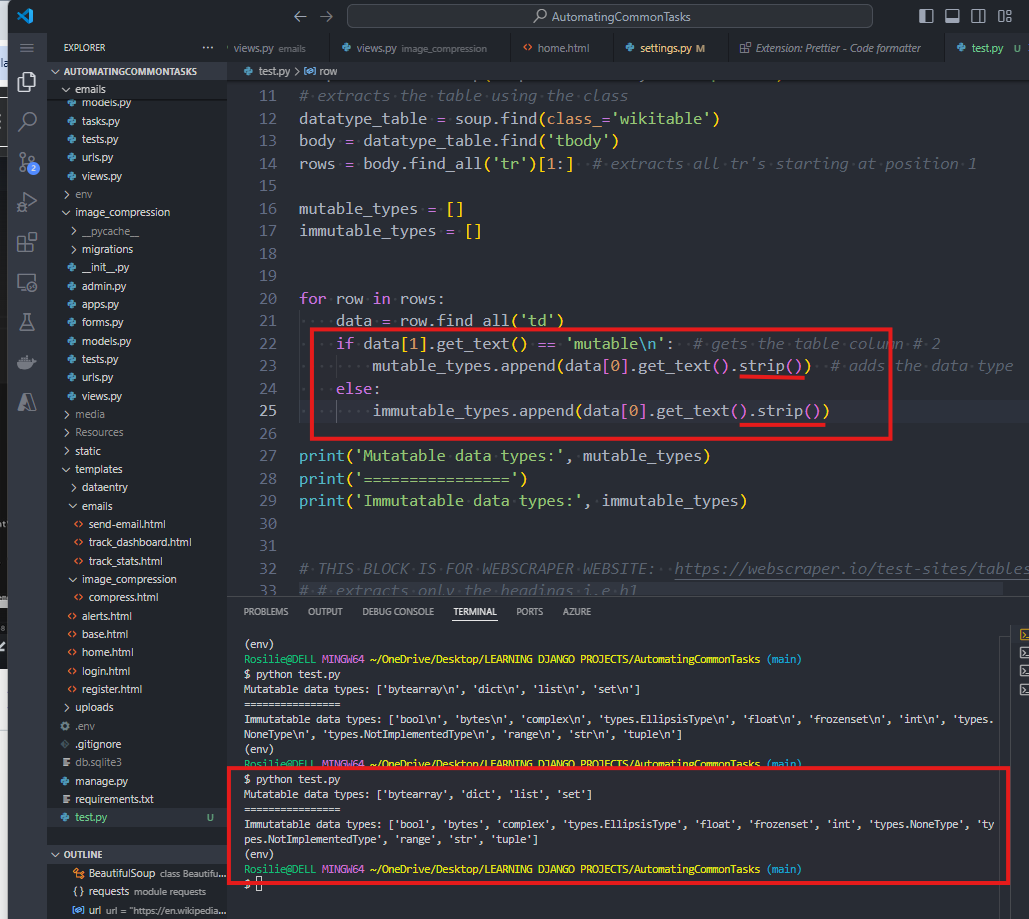
16. These information are needed for STOCK MARKET ANALYSIS.
No PDF file attached.
